The Need for Speed
Reflective prompt optimization—using an LLM to critique and improve another LLM's prompt—is a powerful technique. The original GEPA paper demonstrated that this approach can outperform reinforcement learning. However, for production engineering, wall-clock time is often the bottleneck. We wanted to reach the optimal prompt and temperature settings as rapidly as possible, even if it meant using more tokens.
TurboGEPA is our answer. It takes GEPA's core reflective optimization approach and wraps it in a high-concurrency async architecture.
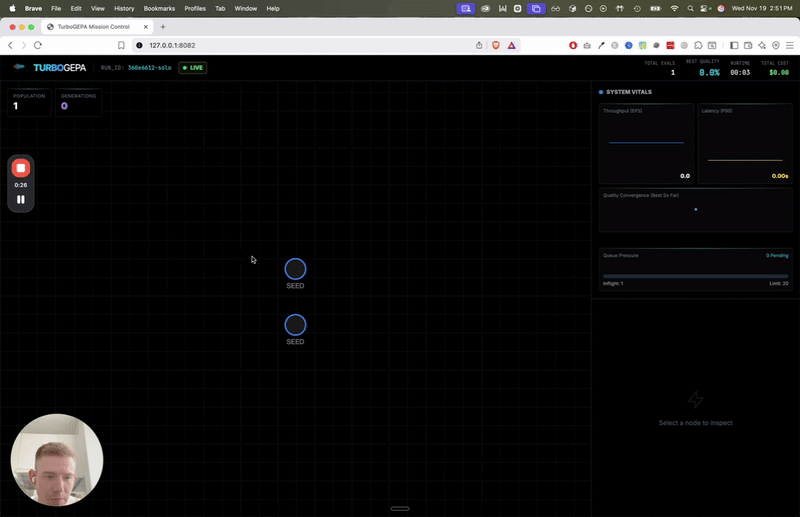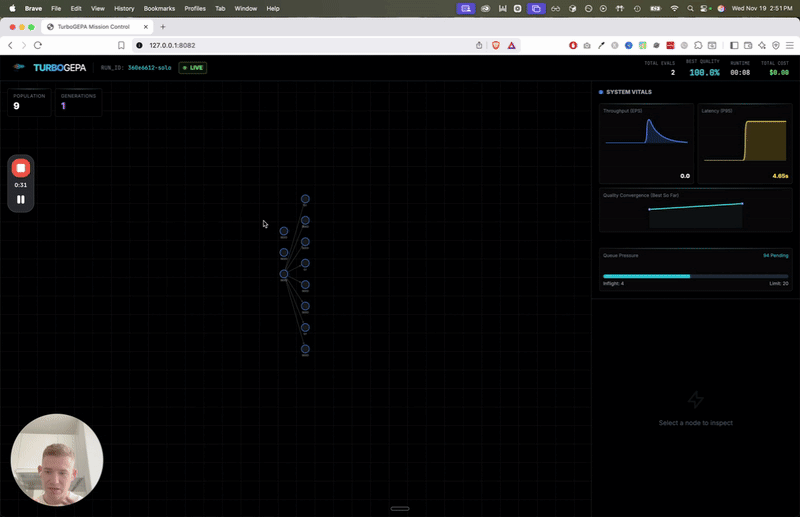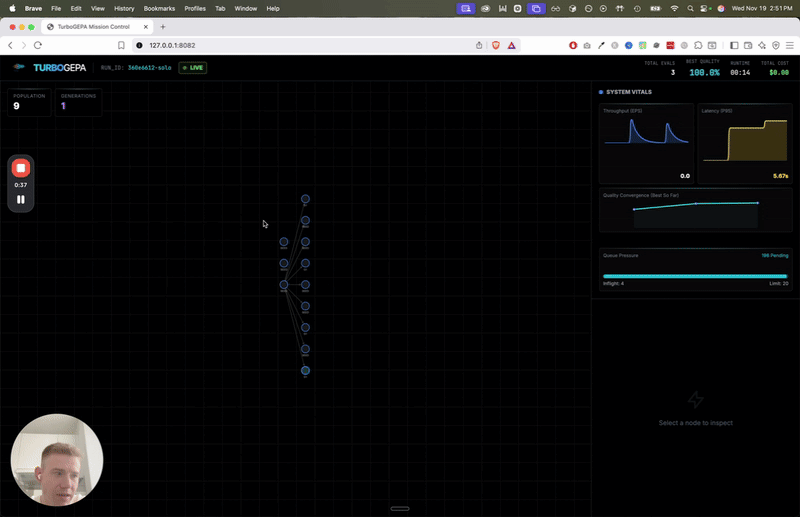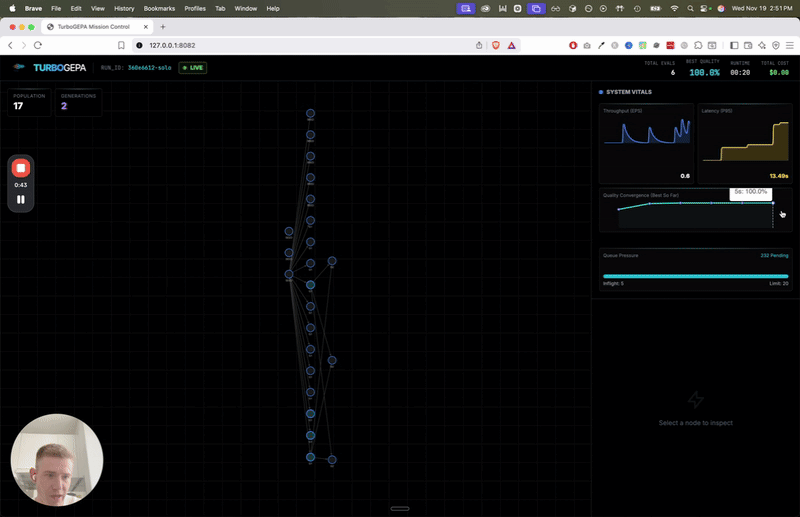
17× Faster
On the OSS-20/Grok-4 benchmark, TurboGEPA reached the target quality in 38s vs 657s for classic GEPA.
Island Parallelism
Concurrent "islands" of evolution broadcast elite candidates to each other, preserving diversity without slowing down.
What Makes It "Turbo"?
While preserving the core innovation of LLM-based reflection, TurboGEPA introduces several architectural changes:
- Maximized Concurrency: Async orchestration scales to your available compute, bounded only by shard size and rate limits.
- ASHA Successive Halving: We prune underperforming prompts early. Instead of running every candidate on the full dataset, we start small and only promote the winners.
- Dual Mutation Strategy: We blend standard reflection (fixing specific errors) with Prompt-MII style spec induction (generating entirely new approaches from examples).
Benchmarks
We ran a head-to-head comparison using the AIME dataset (30 examples) with gpt-oss-20b as the task model and grok-4-fast as the optimizer.
| System | Time-to-Target | Candidates Explored | Result Quality |
|---|---|---|---|
| GEPA (Classic) | ~657s | 3 | 0.733 |
| TurboGEPA | ~38s (17× Faster) | 17 (6× More) | 0.830 |
TurboGEPA not only hit the target faster but explored significantly more of the prompt space, resulting in a prompt that generalized better to the validation set.
Quick Start
You can install TurboGEPA directly from our repository. It is designed to work with any OpenAI-compatible API (OpenRouter, vLLM, etc.).
git clone https://github.com/Studio-Intrinsic/turbo-gepa.git
cd turbo-gepa
uv sync --extra dev --python 3.11
source .venv/bin/activateHere is how to run a simple optimization loop:
from turbo_gepa.adapters import DefaultAdapter
# Create adapter with automatic configuration
adapter = DefaultAdapter(
dataset=trainset,
task_lm="openrouter/openai/gpt-oss-120b:nitro", # Student model (fast, cheap)
reflection_lm="openrouter/x-ai/grok-4-fast" # Optimizer model (fast, smart)
)
# Optimize with multi-island parallelism
result = adapter.optimize(
seeds=["You are a helpful assistant."],
max_rounds=10
)
# Extract the best candidate
entries = result.get("pareto_entries", [])
if entries:
best = max(entries, key=lambda e: e.result.objectives.get("quality", 0.0))
print(f"Best prompt: {best.candidate.text}")Best Practices: Optimize Cheap, Deploy Expensive
One of the most effective patterns we've found is optimizing using smaller, faster models and then transferring the prompt to your production model.
- Optimize: Use TurboGEPA with a fast "student" model (e.g.,
gpt-oss-120b) and a smart "reflection" model (e.g.,grok-4-fast). - Transfer: Take the resulting prompt and use it with your larger production model (e.g., GPT-4o or Claude 3.5 Sonnet).
Recent research shows that prompt optimizations transfer effectively. You save 10-100× on optimization costs while maintaining production quality.
Credits & Acknowledgments
TurboGEPA is built on the shoulders of giants.
- Original GEPA Algorithm: All credit for the core reflective mutation strategy goes to Agrawal et al. (2025). Read the paper.
- Prompt-MII: Our spec induction operator is inspired by the work of Xiao et al. (2025). Read the paper.