GEPA Shows OCR is Steerable for Business Document Pipelines
Modern OCR pipelines can now self-improve via reflective prompt optimization—no retraining required. We show how GEPA delivers consistent gains on business document families by encoding policy, structure, and non-hallucination directly into prompts.
TL;DR
- OCR is steerable in practice for family-similar enterprise documents.
- GEPA (a reflective prompt optimizer) yields +3.3–3.6 point accuracy gains.
- Most improvement comes from the language stage (Markdown → JSON).
- Perception-stage limits persist on degraded scans; typical inputs benefit most.
- Optimize once on a lower-cost model; gains transfer well to larger models.
Why This Matters
Document pipelines suffer from compounding error: five stages at 90% each yields roughly 59% end-to-end reliability. Our goal was practical—could an automatic prompt optimization layer materially shift outcomes without retraining, and under what conditions? With frontier models, the answer is yes for structured extraction on recurring document families.
Benchmark and Pipeline
- Benchmark: Omni OCR Benchmark (1,000 real-world documents with ground-truth JSON)
- Architecture: Image → Markdown (Gemini 2.0 Flash) and Markdown → JSON (LLM)
- Metric: Field-level accuracy penalizing additions, deletions, and modifications
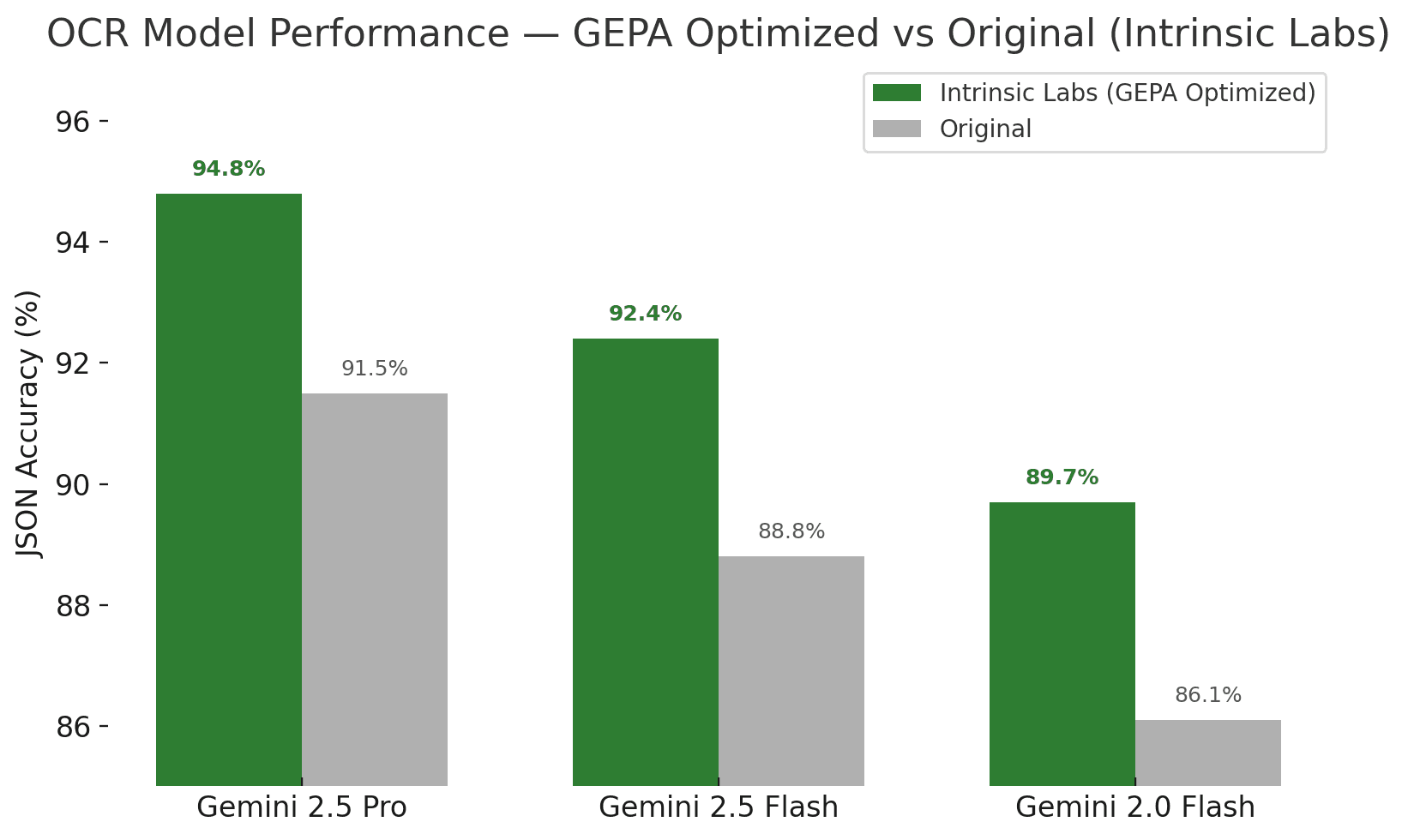
- Baselines: 86.1% (Gemini 2.0 Flash), 88.8% (2.5 Flash), 91.5% (2.5 Pro)
GEPA: Reflective Prompt Evolution
GEPA (Generative Error–Prompt Alignment) treats prompts as optimizable artifacts. It runs candidates on a validation slice, reflects on failures to propose edits, and iteratively advances a Pareto frontier balancing accuracy and prompt simplicity. We used a minimal DSPy fork to enable per-run system prompts and expose document image URLs to the reflection model for context-aware feedback.
Results
- Gemini 2.0 Flash: 86.1% → 89.7% (+3.6)
- Gemini 2.5 Flash: 88.8% → 92.4% (+3.6)
- Gemini 2.5 Pro: 91.5% → 94.8% (+3.3)
On structured subsets, we observed a Pareto frontier approaching ~97%, indicating substantial headroom when document families are consistent and policies are explicit. Roughly 80–90% of gains transferred to larger models—supporting a cost-efficient strategy: optimize once on a smaller model, deploy broadly.
Where Steerability Shows Up
Language stage (steerable):
- Schema anchoring and null vs. hallucination policy
- Normalization (dates, currency precision)
- Reconciliation (e.g., subtotal equals sum of line items)
- Read-order and block grouping
Vision stage (bounded by input):
- Missed tokens and corrupt text remain limited by scan quality
When This Works Best
- Family-similar documents (recurring vendor templates, forms)
- Strict, validated schemas with reconciliation rules
- Explicit policies for read-order, null handling, and totals
- Reasonable perception quality (print clarity, minimal artifacting)
The Optimized Prompt
GEPA converged on a policy prompt that encodes coverage, ordering, schema discipline, and non-hallucination—exactly the levers that drive production reliability.
Convert the provided document image to Markdown. Return only the Markdown with no explanation text.
Rules
1) Coverage and reading order
- Include everything visible: titles, headings, subheadings, headers/footers, page numbers, body text, labels and field values, notes/disclaimers, legends/captions, axis titles, stamps, logos (visible text only), watermarks (visible text only), and any text embedded in charts/graphs/infographics.
- Preserve the original reading order (top-to-bottom, left-to-right). Keep related content together and place captions/headings immediately before their figures.
- Do not omit or invent any content.
2) Headings and hierarchy
- Render the main document/page title as H1 (# …) exactly as printed.
- Use H2/H3 (##, ###) for subordinate section labels according to visual prominence.
- Keep heading text exactly as shown (punctuation, casing, typos unchanged).
- Separate logical blocks with a single blank line.
3) Text blocks, labels, and line breaks
- Preserve meaningful line breaks. Do not arbitrarily merge or split lines.
- Keep each labeled field on its own line unless the source prints multiple labels/values on the same line.
- Preserve punctuation, casing, hyphenation, and spacing exactly as printed.
- Preserve typographic emphasis that conveys structure: use Markdown bold/italic only when clearly present.
4) Tables
- Use a Markdown table for standard tabular data with clear columns/rows.
- Use HTML <table> only when needed to preserve merged cells or nested tables.
- Do not convert simple form layouts into tables. Transcribe as labeled lines.
- Preserve column order, header labels, and units exactly as printed.
- If a cell is blank, output an empty cell.
5) Numbers and units
- Copy values exactly, including currency symbols, separators, decimals, and units.
6) Charts and infographics
- Add one concise, factual alt-text line using Markdown image syntax without a URL.
- Include readable data tables only when printed data is clearly visible.
- Do not invent or estimate values.
7) Logos, watermarks, stamps, and page numbers
- Transcribe visible text exactly as printed.
8) Checkboxes
- Render unchecked as ☐ and checked as ☑. Keep each adjacent to its label.
9) Unreadable or ambiguous content
- Do not guess. Use 'unreadable' in place of illegible text.
10) Consistency and formatting
- Maintain one coherent Markdown style across the document.
- Preserve meaningful line breaks and ordering.
- Do not transform text into lists unless explicitly printed.
11) Prohibitions
- Do not add explanations, commentary, or metadata.
- Do not correct spelling or formatting.
- Do not fabricate content.Deployment Checklist
- Define a strict JSON schema, null policy, and reconciliation checks.
- Establish a held-out validation slice with per-field metrics.
- Run configuration hygiene before optimization (models, scaffolding).
- Optimize teachable subsets (0.70–0.90 baseline) to control cost.
- Add runtime guardrails (schema validator, subtotal sums, date sanity).
- Monitor vendor/form drift; refresh prompts on distribution shift.
Links
Conclusion
OCR is a steerable target for production AI when documents are family-similar and outputs are schema-constrained. With GEPA, we saw +3.3–3.6 point gains and stronger stability—enough to reduce exception handling at scale. A reflective, prompt-optimized layer lets your pipeline improve as models advance—without retraining.